 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEIDNet: Multimodal generative AI framework for inverse materials design
Jan 29, 2026In this work, we present Multimodal Equivariant Inverse Design Network (MEIDNet), a framework that jointly learns structural information and materials properties through contrastive learning, while encoding structures via an equivariant graph neural network (EGNN). By combining generative inverse design with multimodal learning, our approach accelerates the exploration of chemical-structural space and facilitates the discovery of materials that satisfy predefined property targets. MEIDNet exhibits strong latent-space alignment with cosine similarity 0.96 by fusion of three modalities through cross-modal learning. Through implementation of curriculum learning strategies, MEIDNet achieves ~60 times higher learning efficiency than conventional training techniques. The potential of our multimodal approach is demonstrated by generating low-bandgap perovskite structures at a stable, unique, and novel (SUN) rate of 13.6 %, which are further validated by ab initio methods. Our inverse design framework demonstrates both scalability and adaptability, paving the way for the universal learning of chemical space across diverse modalities.
SciQu: Accelerating Materials Properties Prediction with Automated Literature Mining for Self-Driving Laboratories
Jul 11, 2024Assessing different material properties to predict specific attributes, such as band gap, resistivity, young modulus, work function, and refractive index, is a fundamental requirement for materials science-based applications. However, the process is time-consuming and often requires extensive literature reviews and numerous experiments. Our study addresses these challenges by leveraging machine learning to analyze material properties with greater precision and efficiency. By automating the data extraction process and using the extracted information to train machine learning models, our developed model, SciQu, optimizes material properties. As a proof of concept, we predicted the refractive index of materials using data extracted from numerous research articles with SciQu, considering input descriptors such as space group, volume, and bandgap with Root Mean Square Error (RMSE) 0.068 and R2 0.94. Thus, SciQu not only predicts the properties of materials but also plays a key role in self-driving laboratories by optimizing the synthesis parameters to achieve precise shape, size, and phase of the materials subjected to the input parameters.
Chip Placement with Deep Reinforcement Learning
Apr 22, 2020

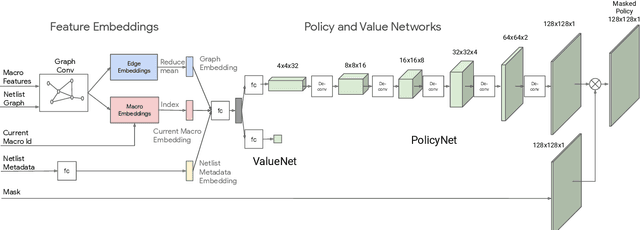
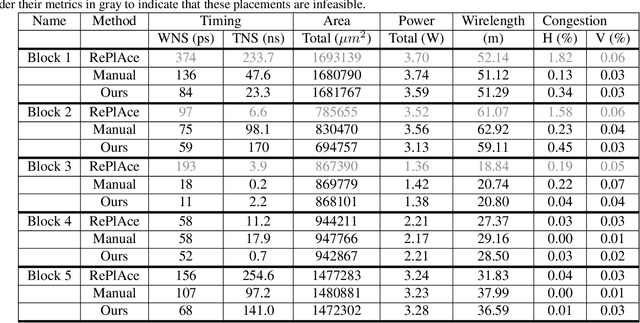
In this work, we present a learning-based approach to chip placement, one of the most complex and time-consuming stages of the chip design process. Unlike prior methods, our approach has the ability to learn from past experience and improve over time. In particular, as we train over a greater number of chip blocks, our method becomes better at rapidly generating optimized placements for previously unseen chip blocks. To achieve these results, we pose placement as a Reinforcement Learning (RL) problem and train an agent to place the nodes of a chip netlist onto a chip canvas. To enable our RL policy to generalize to unseen blocks, we ground representation learning in the supervised task of predicting placement quality. By designing a neural architecture that can accurately predict reward across a wide variety of netlists and their placements, we are able to generate rich feature embeddings of the input netlists. We then use this architecture as the encoder of our policy and value networks to enable transfer learning. Our objective is to minimize PPA (power, performance, and area), and we show that, in under 6 hours, our method can generate placements that are superhuman or comparable on modern accelerator netlists, whereas existing baselines require human experts in the loop and take several weeks.